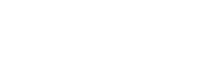

Recent self-supervised learning methods are powerful and efficient for yielding robust representation learning by maximizing the similarity across different augmented views in embedding vector space. However, the main challenge is generating different views with random cropping; the semantic feature might exist differently across different views leading to inappropriately maximizing similarity objective. We tackle this problem by introducing a new framework called Heuristic Attention Representation Learning (HARL), a self-supervised method based on the symmetry optimization of join embedding architecture in which the two neural networks are trained to produce similar embedding for different augmented views of the same image. HARL framework adopts prior visual attention object-level by generating a heuristic mask proposal for each training image and maximizes the abstract object-level embedding on vector space instead of whole image representation from previous works. As a result, HARL extracts the quality semantic representation from each training sample and outperforms self-supervised baselines on several downstream tasks. In addition, we provide efficient techniques based on conventional machine learning and deep learning methods for generating proposal heuristic masks on natural image datasets.
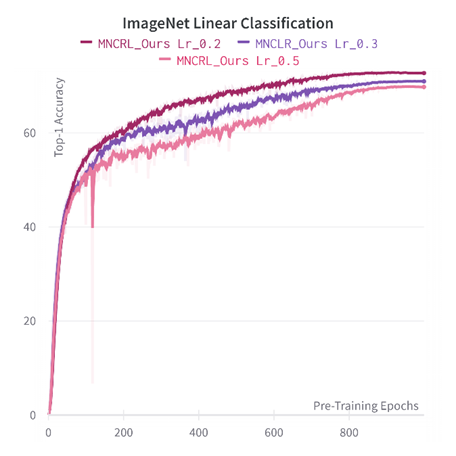
Pre-train : https://wandb.ai/mlbrl/solo/reports/Pretrain-Report–VmlldzoyMTk2NDM5
Ablation : https://wandb.ai/mlbrl/solo/reports/Ablation_Report–VmlldzoxNzU0NjUy
Classification:
Object detection and semantic segmentation:

Our heuristic mask proposal-generated does not rely on external supervision or trained with the limited annotated dataset. We proposed two approaches using conventional machine learning and unsupervised deep learning to generate masks, and these methods are well generalizations of various image datasets. First, we use traditional machine learning DRFI to generate a diverse set of binary masks by varying the two hyperparameters, the Gaussian filter variance σ, and the minimum cluster size s. In our implementation, we defined σ = 0.8 and s = 1000 for generating binary masks in the ImageNet dataset.
In the second approach, we leverage the self-supervised pretraining encoder feature extractor from Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals, then pass the output feature maps into a 1 x 1 convolutional classification layer for saliency prediction. The classification layer predicts the saliency or “foreground-ness” of a pixel. Therefore, we take the output values of the classification layer and set a threshold of 0.5 to decide which pixels belong to the foreground. Pixel saliency values greater than the threshold are determined as foreground objects. The figure shows the example heuristic mask generated by these two methods.


DRFI : https://drive.google.com/file/d/1-WCt2a4jhLWhiyJbfwY7sPsXYQg2TjxF/view?usp=sharing
Unsupervised Deep Learning : https://drive.google.com/file/d/1-Ph6f4lLVe9Og_6_Ko2vx4sSDYKO6b7C/view?usp=sharing

title={Heuristic Attention Representation Learning for Self-Supervised Pretraining},
author={Tran, Van Nhiem and Liu, Shen-Hsuan and Li, Yung-Hui and Wang, Jia-Ching},
journal={Sensors},
volume={22},
number={14},
pages={5169},
year={2022},
publisher={MDPI}
}