新一波人工智慧技術的興起帶來了更多便利的應用,對於人類的影響也越來越多,而人們對於資安及隱私議題也開始重視,如何在隱私優先的安全環境下,有效開發出具效益的人工智慧系統也成為最大的挑戰。聯邦學習是近來提到隱私保護時,備受討論與關注的機器學習技術,其特點及應用又是如何呢?
IEEE聯邦學習標準制定委員會副主席馮霽,3月3日在鴻海研究院所與人工智慧科技基金會舉辦的AI Security論壇上,以「下一代分布式AI協同合作範式兼談AI系統安全」為題,詳細說明了聯邦式學習的特點、應用及安全對策等內容。
聯邦學習的三大特點:隱私保護、端部定製及協同合作
因應世界各國重視數據隱私保護而發展出來的聯邦學習,是近期學術研究中備受矚目的熱門技術議題,目前主要應用於智慧金融、智慧醫療、政府合作、跨機構合作等場景中。「透過只將數據留在本地訓練模型,並對模型進行聯合訓練的分布式場景方式,達到保護隱私的目的。」馮霽解釋。
目前在隱私保護下的數據使用,主要有四種流派,分別是多方安全計算(MPC)、差分隱私(DP)、安全屋(TEE)及聯邦學習。馮霽說,密碼學或者說理論計算機學的多方安全計算(MPC)的技術,雖然在理論上有比較漂亮的結果,但在現實或是較複雜的狀況下,較難落地實現。其次的差分隱私(DP)技術則是難以兼顧數據隱私及模型效果,目前仍有許多人投入相關研究中。另一方面,硬體層面的安全屋(TEE)則是已在英特爾(Intel)或其他開源晶片中實現。最後就是AI模型的聯邦學習,包括以深度神經網絡、決策樹為核心所建構的純軟體方式,這是目前最重要也最高效的技術。
隱私保護、端部定製及協同合作是聯邦學習的三大特點,馮霽提到,隨著歐盟、美國、中國等各國數據治理法規的推出,能透過聯邦學習達到隱私保護的需求。其次,端部定製主要針對客戶端或AIOT等嵌入式的行為,可以根據端部輸入的資料滿足個人化的需求。例如手機用戶在輸入文字時,讓用戶的輸入過程只保存在各自手機中,讓端部的模型和雲端模型不同,並能對用戶微調提供特製的文字推薦。協同合作則是讓客戶端、企業端、政府端在保證數據不出本地的情況下,機構間的數據透過共同模型的參數更新與傳遞,依然能達到協同合作的目的。
聯邦學習的三大挑戰:防禦、資料、去中心化
馮霽指出,聯邦學習目前主要有三大研究重點,其一是如何防禦攻擊者侵入?例如攻擊者侵入訓練過程,透過侵入監聽通訊系統的梯度或參數訊息,恢復或還原數據樣本進而可能造成資料外洩的危機。又或者,當訓練資料被攻擊者進行微幅的擾動,也可能影響模型的結果。馮霽指出,結合密碼學的知識,對於系統進行同態加密仍是目前主要手段。
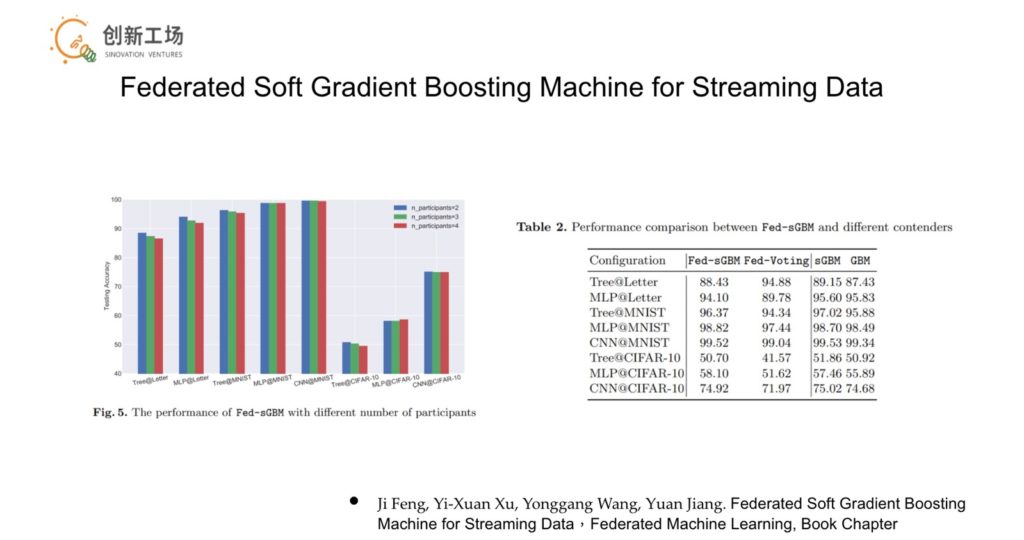
第二則是如何針對非獨立同分佈(Non-I.I.D)的資料進行聯邦式學習,尤其面對串流資料(streaming data),這類隨著時間流逝,分佈產生變化的資料。馮霽提到,他的工作團隊也曾經藉由Gradient Boosting Machine的設計,處理數據遷移的情況。
最後則是如何實現去中心化網絡拓樸結構的聯邦學習架構。主要是除去以中央伺服器儲存參與方的非數據知識,只讓參與方之間進行有限的網路通訊,甚至讓部分參與方沒有網路連接,目前學術界也已提出一系列的版本,希望能實現該架構。
人工智慧的安全與隱私已是重要課題
馮霽指出,隨著人工智慧的應用逐漸從垃圾信件分類等低風險類型,擴大至自動駕駛、軍事應用等高風險應用,以致其安全問題逐漸受到重視。常見的攻擊類型包括:測試階段攻擊以及訓練階段攻擊。馮霽說,測試階段攻擊主要是透過對抗樣本,針對訓練模型的特點進行惡意樣本生成任務,透過對抗樣本讓自駕車錯誤判別路牌。另一方面,訓練階段攻擊則是在模型訓練進行前,透過修改訓練集,以期望操控對應分類器的行為。例如透過改動最小量的訓練數據,使得訓練後的模型在乾淨測試集上表現較差。
由於人工智慧的安全與資料隱私保護已經是個重要的問題,馮霽與創新工廠除了主導制訂第一個IEEE人工智慧協同合作與隱私保護標準,也在2021年5月在IEEE正式啟動AI安全標準大綱。他指出,雖然許多企業對聯邦學習感興趣,但如何在不同機構、不同聯邦學習或數據安全架構下建立合作框架;以及不同場景該選擇何種方案?這些都是未來的挑戰。馮霽認為,更重要的是,如何建立指導手冊並列舉風險,讓不同需求的用戶都能了解風險並及早準備因應措施,這些都是未來需要努力的方向,也需要更多人一起加入,協助建立適用的標準系統。